向量数据库
为了简单起见,此概念概述侧重于基于文本的索引和检索。然而,嵌入模型可以是多模态的,向量数据库可以用于存储和检索文本以外的各种数据类型。
概述
向量数据库是专门的数据存储,能够基于向量表示来索引和检索信息。
这些向量称为嵌入,捕获了已嵌入数据的语义含义。
向量数据库经常用于搜索非结构化数据,例如文本、图像和音频,以基于语义相似性而非精确的关键字匹配来检索相关信息。
集成
LangChain 拥有大量的向量数据库集成,允许用户轻松切换不同的向量数据库实现。
接口
LangChain 提供了用于向量数据库的标准接口,允许用户轻松切换不同的向量数据库实现。
该接口包含用于在向量数据库中写入、删除和搜索文档的基本方法。
关键方法是
add_documents:将文本列表添加到向量数据库。delete:从向量数据库中删除文档列表。similarity_search:搜索与给定查询相似的文档。
初始化
LangChain 中的大多数向量在初始化向量数据库时接受嵌入模型作为参数。
我们将使用 LangChain 的 InMemoryVectorStore 实现来说明 API。
from langchain_core.vectorstores import InMemoryVectorStore
# Initialize with an embedding model
vector_store = InMemoryVectorStore(embedding=SomeEmbeddingModel())
添加文档
要添加文档,请使用 add_documents 方法。
此 API 适用于 Document 对象列表。 Document 对象都具有 page_content 和 metadata 属性,使其成为存储非结构化文本和关联元数据的通用方式。
from langchain_core.documents import Document
document_1 = Document(
page_content="I had chocalate chip pancakes and scrambled eggs for breakfast this morning.",
metadata={"source": "tweet"},
)
document_2 = Document(
page_content="The weather forecast for tomorrow is cloudy and overcast, with a high of 62 degrees.",
metadata={"source": "news"},
)
documents = [document_1, document_2]
vector_store.add_documents(documents=documents)
您通常应该为您添加到向量数据库的文档提供 ID,这样您就可以更新现有文档,而不是多次添加相同的文档。
vector_store.add_documents(documents=documents, ids=["doc1", "doc2"])
删除
要删除文档,请使用 delete 方法,该方法接受要删除的文档 ID 列表。
vector_store.delete(ids=["doc1"])
搜索
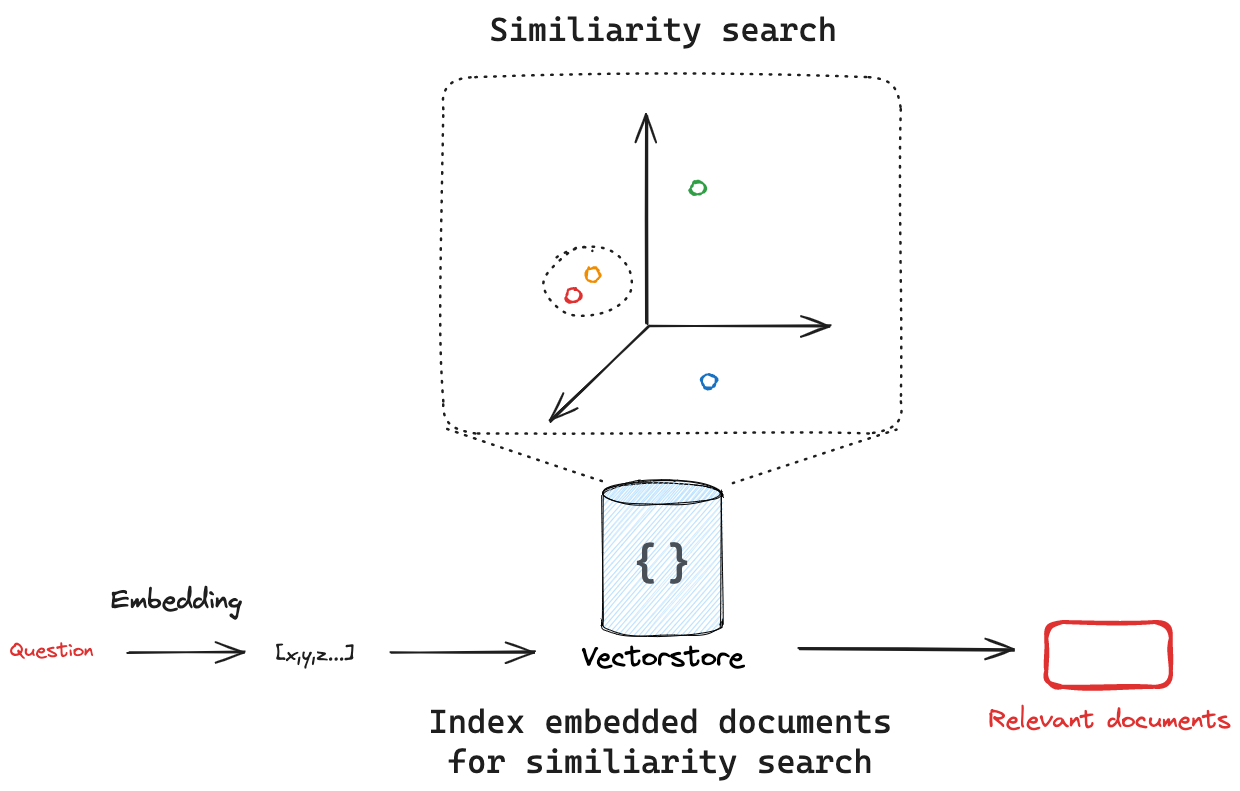
向量数据库嵌入并存储添加的文档。如果我们传入一个查询,向量数据库将嵌入查询,对嵌入的文档执行相似性搜索,并返回最相似的文档。这捕获了两个重要的概念:首先,需要有一种方法来衡量查询与任何嵌入文档之间的相似性。其次,需要有一种算法来有效地对所有嵌入文档执行此相似性搜索。
相似性度量
嵌入向量的一个关键优势是可以使用许多简单的数学运算来比较它们
- 余弦相似度:测量两个向量之间角度的余弦值。
- 欧几里得距离:测量两点之间的直线距离。
- 点积:测量一个向量在另一个向量上的投影。
相似性度量的选择有时可以在初始化向量数据库时选择。请参阅您正在使用的特定向量数据库的文档,以查看支持哪些相似性度量。
相似性搜索
给定一个相似性度量来测量嵌入的查询与任何嵌入文档之间的距离,我们需要一种算法来有效地搜索所有嵌入文档以找到最相似的文档。有很多方法可以做到这一点。例如,许多向量数据库实现了 HNSW(分层可导航小世界),这是一种基于图的索引结构,可以实现高效的相似性搜索。无论底层使用哪种搜索算法,LangChain 向量数据库接口都为所有集成提供了 similarity_search 方法。这将接受搜索查询,创建嵌入,查找相似的文档,并将它们作为 Documents 列表返回。
query = "my query"
docs = vectorstore.similarity_search(query)
许多向量数据库支持与 similarity_search 方法一起传递的搜索参数。请参阅您正在使用的特定向量数据库的文档,以查看支持哪些参数。例如 Pinecone 几个重要的通用概念参数:许多向量数据库支持 k,它控制要返回的文档数量,以及 filter,它允许按元数据过滤文档。
query (str) – 要查找与其相似的文档的文本。k (int) – 要返回的文档数量。默认为 4。filter (dict | None) – 要按元数据过滤的参数字典。
元数据过滤
虽然向量数据库实现了搜索算法以有效地搜索所有嵌入文档以找到最相似的文档,但许多向量数据库也支持按元数据过滤。元数据过滤通过应用特定条件(例如从特定来源或日期范围检索文档)来帮助缩小搜索范围。这两个概念协同工作得很好
- 语义搜索:直接查询非结构化数据,通常通过嵌入或关键字相似性。
- 元数据搜索:将结构化查询应用于元数据,过滤特定文档。
向量数据库对元数据过滤的支持通常取决于底层向量数据库实现。
这是 Pinecone 的示例用法,显示我们过滤所有具有元数据键 source 且值为 tweet 的文档。
vectorstore.similarity_search(
"LangChain provides abstractions to make working with LLMs easy",
k=2,
filter={"source": "tweet"},
)
- 请参阅 Pinecone 关于使用元数据进行过滤的文档。
- 请参阅支持元数据过滤的LangChain 向量数据库集成列表。
高级搜索和检索技术
虽然像 HNSW 这样的算法在许多情况下为高效的相似性搜索提供了基础,但可以采用其他技术来提高搜索质量和多样性。例如,最大边际相关性是一种重新排序算法,用于使搜索结果多样化,它在初始相似性搜索后应用,以确保更多样化的结果集。作为第二个示例,一些 向量数据库 提供内置的 混合搜索,以结合关键字和语义相似性搜索,从而结合了两种方法的优点。目前,没有统一的方法使用 LangChain 向量数据库执行混合搜索,但它通常作为关键字参数公开,并通过 similarity_search 传入。有关更多详细信息,请参阅关于混合搜索的操作指南。
| 名称 | 何时使用 | 描述 |
|---|---|---|
| 混合搜索 | 当结合基于关键字和语义相似性时。 | 混合搜索结合了关键字和语义相似性,结合了两种方法的优点。论文。 |
| 最大边际相关性 (MMR) | 当需要使搜索结果多样化时。 | MMR 尝试使搜索结果多样化,以避免返回相似和冗余的文档。 |