嵌入模型
本概念性概述侧重于基于文本的嵌入模型。
嵌入模型也可以是多模态的,但目前LangChain不支持此类模型。
想象一下,能够将任何文本——无论是推文、文档还是书籍——的精髓提炼成一个单一、紧凑的表示形式。这就是嵌入模型的力量,它们是许多检索系统的核心。嵌入模型将人类语言转换为机器能够理解并快速准确地进行比较的格式。这些模型将文本作为输入,并生成一个固定长度的数字数组,这是文本语义含义的数值指纹。嵌入允许搜索系统不仅基于关键词匹配,还能基于语义理解来查找相关文档。
关键概念
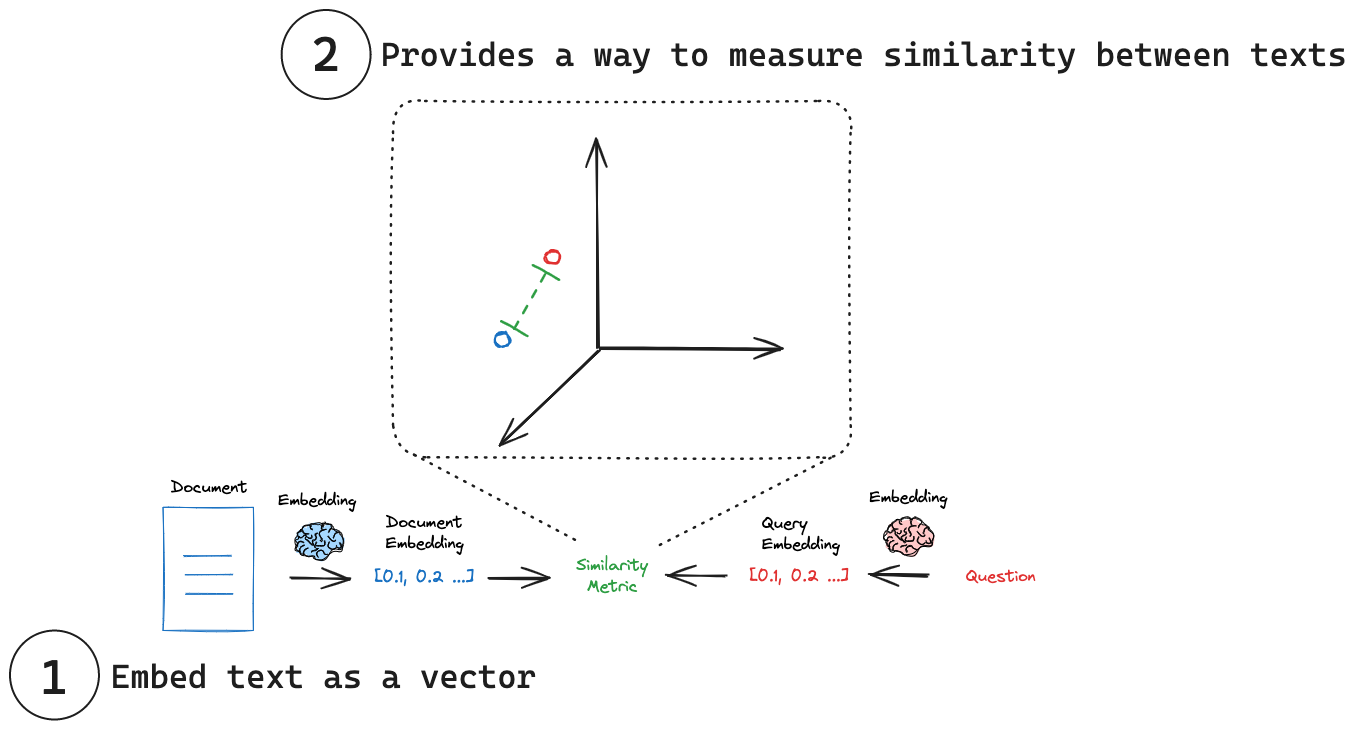
(1) 将文本嵌入为向量:嵌入将文本转换为数值向量表示。
(2) 衡量相似度:嵌入向量可以使用简单的数学运算进行比较。
嵌入
历史背景
嵌入模型领域在过去几年中取得了显著发展。2018年,谷歌推出BERT(来自 Transformers 的双向编码器表示),这是一个关键时刻。BERT应用Transformer模型将文本嵌入为简单的向量表示,这在各种自然语言处理任务中带来了前所未有的性能。然而,BERT并未针对高效生成句子嵌入进行优化。这一限制促使了SBERT(句法BERT)的创建,它调整了BERT架构以生成语义丰富的句子嵌入,通过余弦相似度等相似度指标可以轻松比较,大大降低了查找相似句子等任务的计算开销。如今,嵌入模型生态系统多种多样,众多提供商提供了自己的实现。为了应对这种多样性,研究人员和从业者通常会参考此处的大规模文本嵌入基准(MTEB)等基准进行客观比较。
- 参阅开创性的BERT论文。
- 参阅Cameron Wolfe关于嵌入模型的精彩评论。
- 参阅大规模文本嵌入基准(MTEB)排行榜,以全面了解嵌入模型。
接口
LangChain提供了一个通用接口来处理它们,为常见操作提供了标准方法。这个通用接口通过两种核心方法简化了与各种嵌入提供商的交互
embed_documents:用于嵌入多个文本(文档)embed_query:用于嵌入单个文本(查询)
这种区分很重要,因为一些提供商对文档(待搜索)和查询(搜索输入本身)采用不同的嵌入策略。为了说明这一点,这里有一个使用LangChain的.embed_documents方法嵌入字符串列表的实际示例
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
(5, 1536)
为方便起见,您也可以使用embed_query方法来嵌入单个文本
query_embedding = embeddings_model.embed_query("What is the meaning of life?")
- 参阅LangChain嵌入模型集成的完整列表。
- 参阅这些关于使用嵌入模型的操作指南。
集成
LangChain提供了许多嵌入模型集成,您可以在嵌入模型集成页面找到它们。
衡量相似度
每个嵌入本质上是一组坐标,通常在高维空间中。在这个空间中,每个点(嵌入)的位置反映了其对应文本的含义。正如同义词在同义词典中可能彼此接近一样,相似的概念在这个嵌入空间中也最终会彼此接近。这使得不同文本之间可以进行直观的比较。通过将文本简化为这些数值表示,我们可以使用简单的数学运算快速衡量两段文本的相似程度,而无需考虑其原始长度或结构。一些常见的相似度指标包括
- 余弦相似度:衡量两个向量之间夹角的余弦值。
- 欧几里得距离:衡量两点之间的直线距离。
- 点积:衡量一个向量在另一个向量上的投影。
相似度指标的选择应根据模型来定。例如,OpenAI 建议其嵌入使用余弦相似度,这可以轻松实现
import numpy as np
def cosine_similarity(vec1, vec2):
dot_product = np.dot(vec1, vec2)
norm_vec1 = np.linalg.norm(vec1)
norm_vec2 = np.linalg.norm(vec2)
return dot_product / (norm_vec1 * norm_vec2)
similarity = cosine_similarity(query_result, document_result)
print("Cosine Similarity:", similarity)