检索器
概述
存在多种不同类型的检索系统,包括向量存储、图数据库和关系数据库。随着大型语言模型普及度的提高,检索系统已成为AI应用(例如,RAG)中的重要组成部分。由于其重要性和多样性,LangChain 提供了一个统一的接口,用于与不同类型的检索系统进行交互。LangChain 检索器接口非常直观
- 输入:查询(字符串)
- 输出:文档列表(标准化 LangChain Document 对象)
核心概念
所有检索器都实现了一个简单的接口,用于使用自然语言查询检索文档。
接口
检索器唯一的要求是能够接受查询并返回文档。特别是,LangChain 的检索器类只要求实现 `_get_relevant_documents` 方法,该方法接受 `query: str` 并返回与查询最相关的 Document 对象列表。获取相关文档的底层逻辑由检索器指定,可以是任何对应用程序最有用的逻辑。
LangChain 检索器是可运行的,这是 LangChain 组件的标准接口。这意味着它有一些常用方法,包括 `invoke`,用于与其交互。检索器可以通过查询来调用
docs = retriever.invoke(query)
检索器返回一个 Document 对象列表,这些对象具有两个属性
- `page_content`:此文档的内容。当前为字符串。
- `metadata`:与此文档关联的任意元数据(例如,文档 ID、文件名、来源等)。
- 请参阅我们的操作指南,了解如何构建自己的自定义检索器。
常见类型
尽管检索器接口灵活,但仍有几种常见类型的检索系统被频繁使用。
搜索API
值得注意的是,检索器实际上不需要存储文档。例如,我们可以在搜索 API 之上构建检索器,它们只返回搜索结果!请参阅我们与 Amazon Kendra 或 Wikipedia Search 的检索器集成。
关系型或图数据库
检索器可以构建在关系型或图数据库之上。在这些情况下,将自然语言转换为结构化查询的查询分析技术至关重要。例如,您可以使用 text-to-SQL 转换来为 SQL 数据库构建检索器。这允许将自然语言查询(字符串)检索器在幕后转换为 SQL 查询。
词法搜索
正如我们在检索概念回顾中讨论的,许多搜索引擎都基于将查询中的词与每个文档中的词进行匹配。BM25 和 TF-IDF 是两种流行的词法搜索算法。LangChain 拥有许多流行的词法搜索算法/引擎的检索器。
- 请参阅 BM25 检索器集成。
- 请参阅 TF-IDF 检索器集成。
- 请参阅 Elasticsearch 检索器集成。
向量存储
向量存储是一种强大且高效的索引和检索非结构化数据的方式。通过调用 `as_retriever()` 方法,向量存储可以用作检索器。
vectorstore = MyVectorStore()
retriever = vectorstore.as_retriever()
高级检索模式
集成
由于检索器接口非常简单,给定一个搜索查询时返回一个 `Document` 对象列表,因此可以使用集成方式组合多个检索器。当您有多个擅长查找不同类型相关文档的检索器时,这尤其有用。可以轻松创建集成检索器,它通过线性加权分数组合多个检索器
# Initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_store_retriever], weights=[0.5, 0.5]
)
在集成时,我们如何组合来自多个检索器的搜索结果?这引出了重排序的概念,它接收多个检索器的输出并使用更复杂的算法(例如倒数排名融合 (RRF))将它们组合起来。
源文档保留
许多检索器都利用某种索引来使文档易于搜索。索引过程可能包括转换步骤(例如,向量存储通常使用文档分割)。无论使用何种转换,保留转换后的文档与原始文档之间的链接都非常有用,这使得检索器能够返回原始文档。
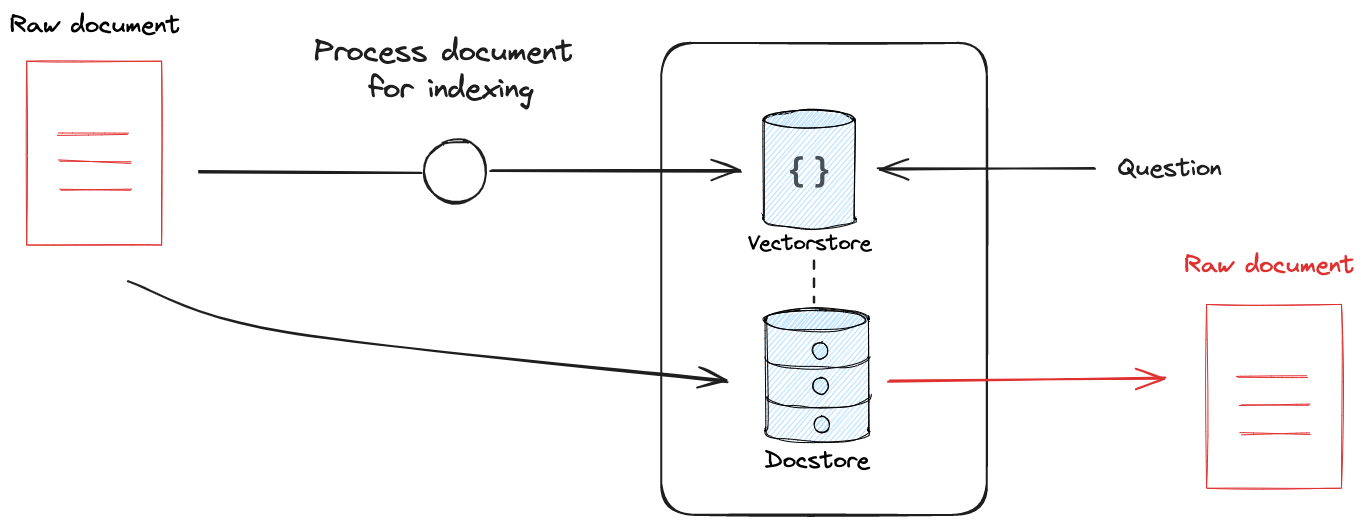
这在 AI 应用中特别有用,因为它确保了模型在文档上下文方面没有损失。例如,您可以在向量存储中对文档进行索引时使用小块大小。如果仅将这些块作为检索结果返回,则模型将丢失这些块的原始文档上下文。
LangChain 提供了两种不同的检索器来应对这一挑战。多向量(Multi-Vector)检索器允许用户使用任何文档转换(例如,使用 LLM 编写文档摘要)进行索引,同时保留与源文档的链接。父文档(ParentDocument)检索器将来自文本分割器转换的文档块进行索引,同时保留与源文档的链接。
| 名称 | 索引类型 | 使用LLM | 何时使用 | 描述 |
|---|---|---|---|---|
| ParentDocument | 向量存储 + 文档存储 | 否 | 如果您的页面包含许多独立的较小信息片段,这些片段最好单独索引,但最好一起检索。 | 这涉及为每个文档索引多个块。然后找到在嵌入空间中最相似的块,但您检索并返回整个父文档(而不是单独的块)。 |
| Multi Vector | 向量存储 + 文档存储 | 有时在索引期间 | 如果您能够从文档中提取出您认为比文本本身更相关的索引信息。 | 这涉及为每个文档创建多个向量。每个向量可以通过多种方式创建——例如文本摘要和假设性问题。 |